前言
emmm,学了一点点,啊不对,乱摸索了下python,写了一个简单的爬P站图片的脚本,哈哈最近也没什么可以发的教程视频,欸嘿嘿嘿嘿,就用它吧,这里我简单的文字描述一下爬取过程。
接口爬取
首先,我们来说一下F12工具抓包,这个东西非常重要,也是我们筛选接口的必要工具。
搜索接口爬取
按F12,搜索内容,注意右边抓获的数据内容,利用它,我们就可以的抓到P站的数据接口。
搜索接口 https://www.pixiv.net/ajax/search/top/内容?lang=zh
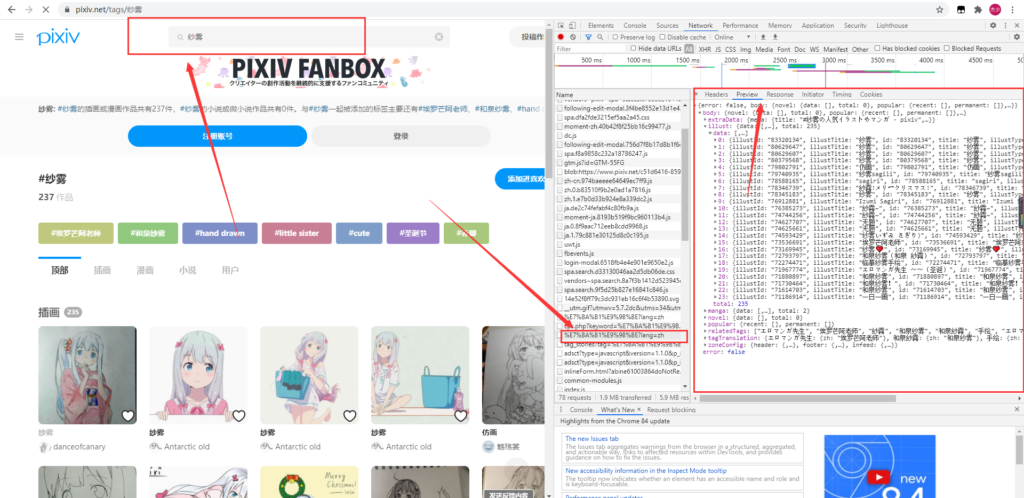
有了简单的接口,我们就可以定位我们需要的数据位置
[‘body’][‘illust’][‘data’]
这个就是我们需要定位的数组,它下面有许多的搜索接口内容,我们通过它来递归循环获取每一组ID。
接口分析
我们发现上面接口的图片不能直接使用,因为他是缩略图,我们现在需要找到正式图片的接口返回地址,因为我们通过上接口可以获取ID,那么我们就先保留ID获取。
个人作品信息接口 https://www.pixiv.net/ajax/illust/ID?lang=zh
有了这个接口我们就可以获取一下这个作品的图片链接
[‘body’][‘urls’][‘original’]
上面的对象就是我们需要的链接,有了链接我们现在就要应对反爬,P站也有爬虫检测,需要传入几个特殊的请求头才能获取到图片,否则403禁止访问。
request.add_header(‘referer’,’https://www.pixiv.net/tags/%E7%BA%B1%E9%9B%BE’)
添加referer信息
只要有它,代表我是从P站内部来的,我要下载,这样就可以正常下载,下面代码里展示了这个函数。
接下来我们万事俱备,就可以直接编写代码了,我们直接看下面。
代码展示
import urllib.request, urllib.error, urllib.parse
import urllib
import demjson
import json
import requests
import time
import socket
def SaveImage(url, path): # 传入的url是图片url地址
request = urllib.request.Request(url) # 模拟浏览器头部信息
request.add_header('accept','image/webp,image/apng,*/*;q=0.8')
request.add_header('accept-encoding','gzip, deflate, br')
request.add_header('accept-language','zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6')
request.add_header('sec-fetch-dest','image')
request.add_header('sec-fetch-mode','no-cors')
request.add_header('sec-fetch-site','cross-site')
request.add_header('referer','https://www.pixiv.net/tags/%E7%BA%B1%E9%9B%BE')
request.add_header('user-agent','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)')
try:
response = urllib.request.urlopen(request) # 打开该url得到响应
img = response.read() # read读取出来
f = open(path, 'wb') # 以二进制写入的格式打开
f.write(img) # 写入
f.close() # 关闭
except urllib.error.URLError as ue: # 捕获urlerror
if hasattr(ue, 'code'): # 如果ue中包含'code'字段, 则打印出来
print(ue.code)
if hasattr(ue, "reason"):# 如果ue中包含'reason'字段, 则打印出来
print(ue.reason)
except IOError as ie:
print(ie)
return
if __name__ == "__main__":
word = input('输入搜索内容')
p = input('输入抓取页码')
s = requests.session()
headers = {
'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)'
}
res = s.get("https://www.pixiv.net/ajax/search/illustrations/"+word+"?word="+word+"&p="+p+"&lang=zh",headers=headers)
string = res.text
list1 = demjson.decode(string)
i = 0
while i < len(list1['body']['illust']['data']) - 1:
id = list1['body']['illust']['data'][i]['id']
headers = {
'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)'
}
s.keep_alive = False # 关闭多余连接
Str = s.get("https://www.pixiv.net/ajax/illust/"+id+"?lang=zh",headers=headers)
string = Str.text
Strjson = demjson.decode(string)
imgurl = Strjson['body']['urls']['original']
print(imgurl)
name = list1['body']['illust']['data'][i]['title']+id
print(name)
path = "F:\下载文件\图片\大马明文版\\"+ name + ".png"
SaveImage(imgurl, path)
i= i + 1
print(i)
time.sleep(5)文末
其实我写的这也是微不足道的,没有很大的参考价值,发文文章和视频也是为了鼓励一下自己学习,展示一下成果而已,当然,我也希望这篇文章和视频可以帮助到你。

{kind=link}
发表回复