前言
本文将教你去搭建一个B站的机器人,具备私信文本和图片的功能,下面本文将教大家完成自己的机器人。
首先我先来说我们用的开源项目 LastOrderBot 这个是我在最近写的一个开源项目,算是一个B站私信机器人框架吧,项目介绍你可以去B站看。
搭建准备
首先让我们先下载源码,这次语言是python
进入GitHub,下载最新的项目源码,我们进行使用
在这里求一个Star星星
下载源码后让我们首先打开 config文件夹下的 config.py
#在这里配置你的机器人操作类中需要的东西,图方便就不写JSON了,大家这样也好理解
class Config:
#机器人发信headers
headers = {
"referer": "https://message.bilibili.com/",
'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
'cookie' : "cookie"
}
#B站账号鉴权 -> cookie 的 bili_jct
csrf_token = 'bili_jct'
#机器人UID
robot_uid = 10086
# TODO 消息刷新心跳 -> 秒数 建议 在 0.5 ~ 3 之内 如果设置为 1 代表每位用户1秒内最多可以发送1条消息,可以同时发送 根据需求加快心跳 太低可能会给B站造成负担,请不要低于0.5
heartbeat_interval = 1
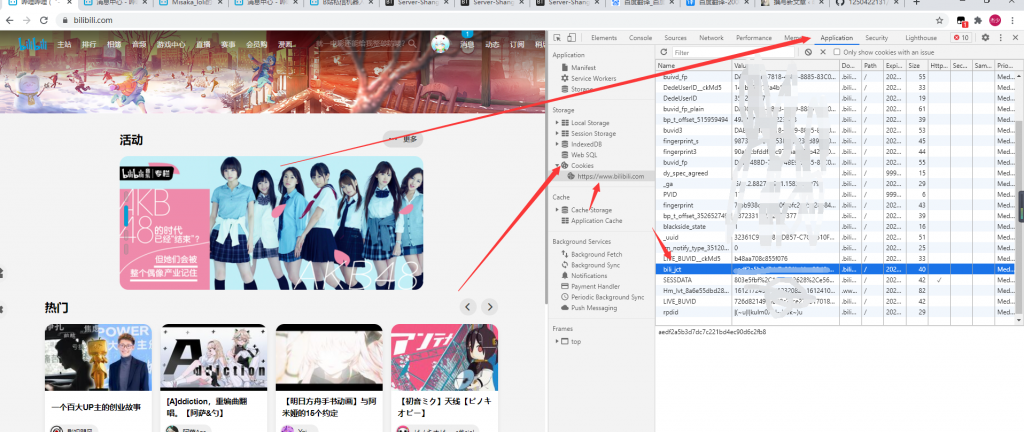
根据注释填写,如果你不会找csrf_token,也就是bili_jct,请看下图,在网页按F12出现调试台,找到bili_jct的值输入。
运行机器人
下面我介绍两种系统运行方式
Windows
下载源码后,请确认自己安装了python环境,版本在3.7及以上,我们这里推荐使用VSCODE来进行编写机器人
我们使用了如下模块
requests demjson PIL 请自行使用pip下载补全模块,如果不会,请百度,我有可能漏写,按照确少的模块自行安装。
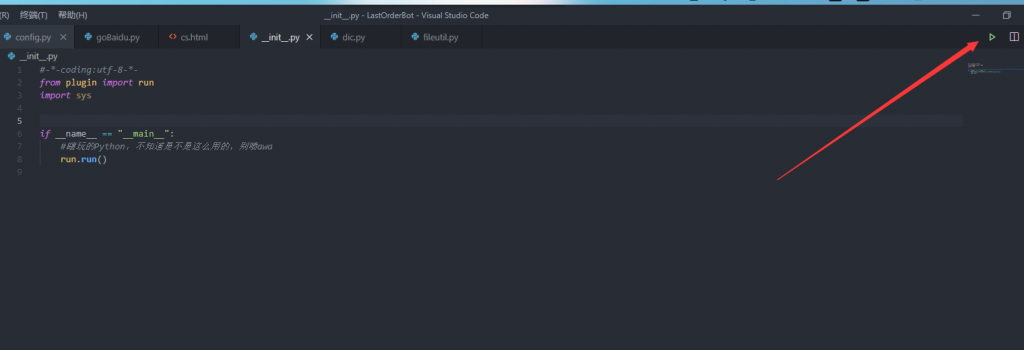
我们回到文件根目录 LastOrderBot 在这个目录下,有_init_.py,运行这个文件,你的机器人就大功告成,并且在运行了,下面我会讲机器人词库如何匹配用户命令。
宝塔 ->CentOS->Linux
我们来看看,首先确定你是CentOS系统,接下来在宝塔应用商店安装 Python项目管理器 ,接着请去安装python3.7及以上的版本。
如果完成了这些操作,请上传下载的源代码到你的一个文件夹,在这个文件夹下新建一个文件,名为 requirements.txt
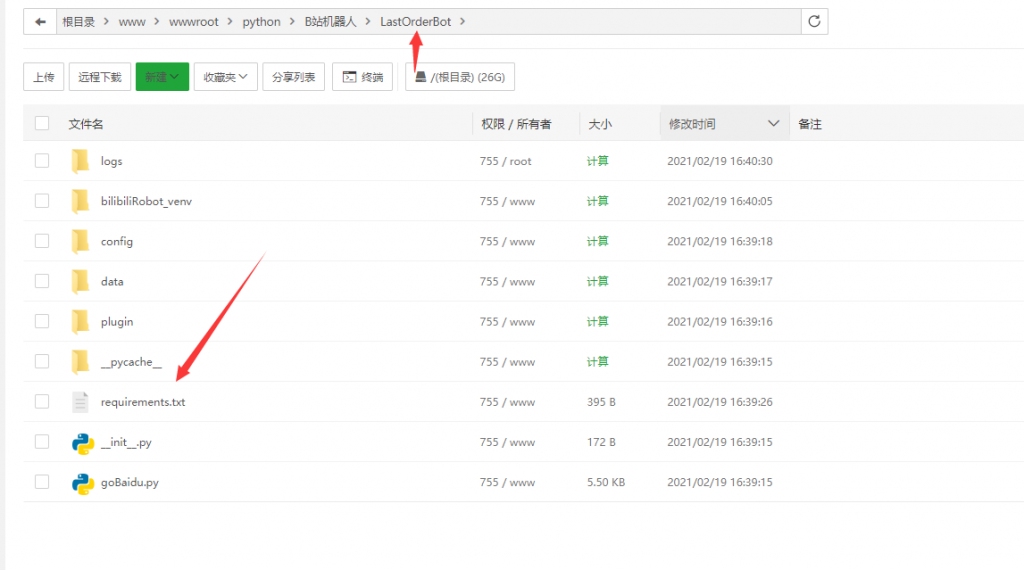
这个文件里需要填写我们使用的第三方模块,也就是让大家使用pip下载的模块
我给大家写个我用的
altgraph==0.17
autopep8==1.5.4
certifi==020.12.5
chardet==4.0.0
demjson==2.2.4
et-xmlfile==1.0.1
future==0.18.2
idna==2.10
jdcal==1.4.1
pefile==019.4.18
Pillow==8.1.0
pip==21.0.1
pycodestyle==2.6.0
pyinstaller==4.1
pyinstaller-hooks-contrib==2020.11
pywin32-ctypes==0.2.0
requests==2.25.1
selenium==3.141.0
setuptools==49.2.1
toml==0.10.2
urllib3==1.26.2这里面有许多可能你用不上,后面可以删掉
如果完成了这些步骤,回到python项目管理器
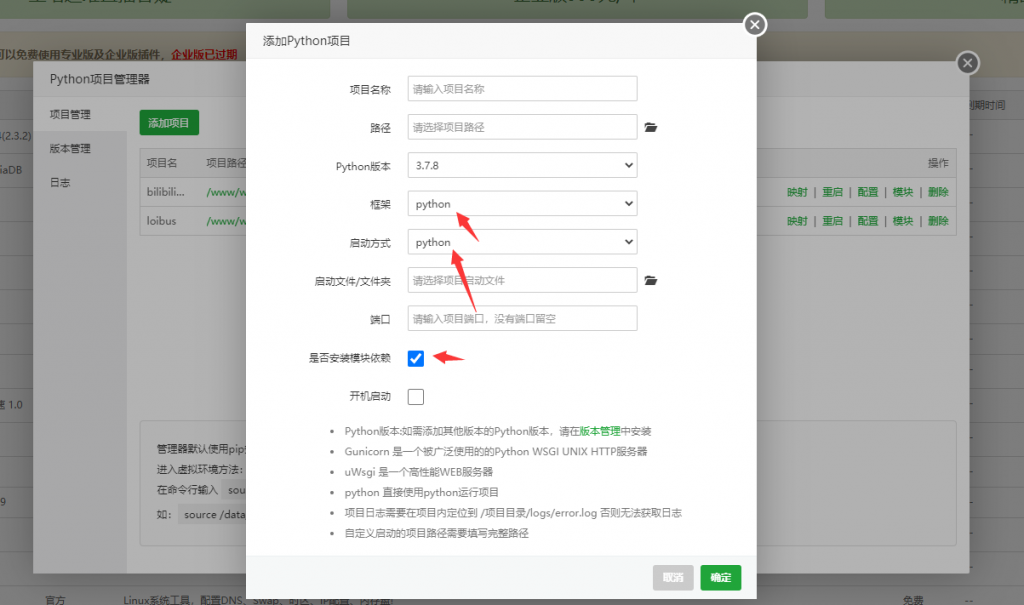
新建项目,按照要求填写,这个目录就是 LastOrderBot ,启动文件为LastOrderBot目录里的_init_.py
完成后你的机器人就在运行当中了
机器人识别用户消息
请找到plugin文件夹里的dic.py,在这里是机器人的词库,匹配用户消息,并且做出回应。
#-*-coding:utf-8-*-
import re
import requests
from plugin.msgutil import MsgUtil
from config.config import Config
from plugin.fileutil import FileUtil
headers = Config.headers
csrf_token = Config.csrf_token
robotUid = Config.robot_uid
msgutil = MsgUtil(headers,csrf_token,robotUid)
fileutil = FileUtil()
#DIC词库内容
def sendText(userMsg,robotUid,senderUid):
if userMsg == "菜单":
Msg = '来份萝莉\n你好 聊天内容'
print(msgutil.sendMsg(Msg,robotUid,senderUid))
msgutil.updateAck(senderUid,csrf_token)
#字符串匹配
if userMsg == "你好":
Msg = "你也好"
#发送者UID 接受UID
print(msgutil.sendMsg(Msg,robotUid,senderUid))
msgutil.updateAck(senderUid,csrf_token)
if userMsg == "你是不是萝莉":
Msg = '不不不,我想不是'
print(msgutil.sendMsg(Msg,robotUid,senderUid))
msgutil.updateAck(senderUid,csrf_token)
if userMsg =="来份萝莉":
imageUrl = msgutil.captureIamgeUrl("https://api.dongmanxingkong.com/suijitupian/acg/1080p/index.php")
imageFormat = msgutil.getImageFormat(imageUrl)
imageWidth = imageFormat[0]
imageHeight = imageFormat[1]
imageFormat = imageFormat[2]
print(msgutil.sendImage(imageUrl,robotUid,senderUid,imageWidth,imageHeight,imageFormat))
msgutil.updateAck(senderUid,csrf_token)
#正则表达式区域
re1 = re.search('^你好 ?(.*?)$', userMsg)
if re1:
MsgRe = re.compile('^你好 ?(.*?)$')
MsgReArray = MsgRe.findall(userMsg)
print(MsgReArray[0])
getMsg = requests.get("http://i.itpk.cn/api.php?question="+str(MsgReArray[0])+"&api_key=45c0866382610cbee9bbbffaef5aa943&api_secret=ffnzr6hrzzaj&limit=8")
getMsg.encoding = 'utf-8'
getMsg = getMsg.text
print(msgutil.sendMsg(getMsg,robotUid,senderUid))
msgutil.updateAck(senderUid,csrf_token)
pass
re2 = re.search('^写入 .*? .*? .*?$', userMsg)
if re2:
MsgRe = re.compile('^写入 (.*?) (.*?) (.*?)$')
MsgReArray = MsgRe.match(userMsg)
fileutil.write(MsgReArray.group(1),MsgReArray.group(2),MsgReArray.group(3))
print(msgutil.sendMsg("写入成功",robotUid,senderUid))
msgutil.updateAck(senderUid,csrf_token)
re3 = re.search('^读出 .*? .*?$', userMsg)
if re3:
MsgRe = re.compile('^读出 (.*?) (.*?)$')
MsgReArray = MsgRe.match(userMsg)
Msg = fileutil.read(MsgReArray.group(1),MsgReArray.group(2))
print(msgutil.sendMsg(Msg,robotUid,senderUid))
msgutil.updateAck(senderUid,csrf_token)
pass
这里我写了一些简单的处理,你可以参照扩充。
文末
这里就教到这个地方了,请大家自己摸索,我的python瞎玩的,没有系统学,写的烂,当你规范后请毫不犹豫的提交分支到GitHub,我将学习大家的经验。
使用请参照 GitHub项目里的开源协议 严禁滥用 使用者自行承担后果。

发表回复